데이터 수집의 종류별 공부 중 API 형태의 데이터 수집으로 네이버 검색 API 수집을 완료했다 이후 웹 스크래핑 형식의 데이터 수집을 진행해보려 한다
웹 스크래핑은 웹 구조를 이용한 데이터 수집 방법으로 흔히 사이트를 긁어온다 라고 표현하며 사이트 별로 구조가 모두 다르기에 웹 페이즈에 대한 구조와 웹 스크래핑을 위한 BS4_BeautifulSoup 라이브러리 사용 경험치가 중요한 작업이다
간단 웹 페이지 구조
1. html5 : 데이터, 뼈대, 구조
2. css : 디자인, 레이아웃, 애니메이션, 반응형 (모바일<->PC)
- bootstrap, 머터리얼 등의 디자인 템플릿도 가능
3. javascript, Ajax : 사용자 상호작용, 이벤트, 화면조작
웹 스크래핑 방법
- html 문자열
- BeautifulSoup 파싱
- html 구조로 메모리에 적재
- 탐색/검색
- 정보 추출
6. 데이터화
데이터 수집 타겟 사이트 선정
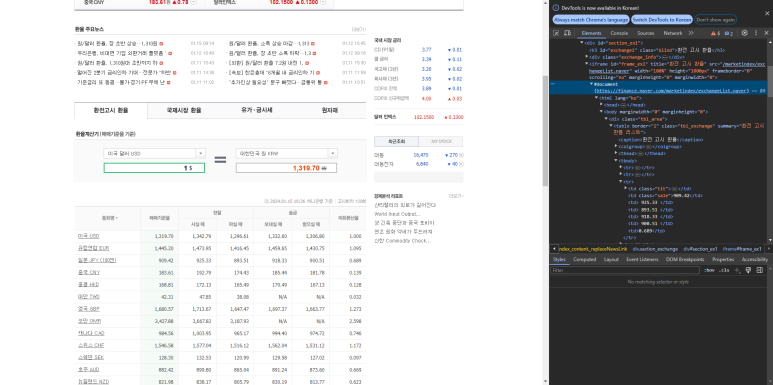
네이버 증권 환율 지표 데이터로 선정 'F12' 키 검사로 들어가서 확인해보면 네이버 환율 사이트는 친절이 document 사이트를 제공해 주어 손쉽게 데이터 수집이 가능 할 것으로 예상되며 최근 엔화의 하락이 있어서 엔화 변동성을 확인하여
엔화 ETF 매수 시점을 잡아보려고 시도중으로 네이버 환율 사이트를 타겟 사이트로 선정
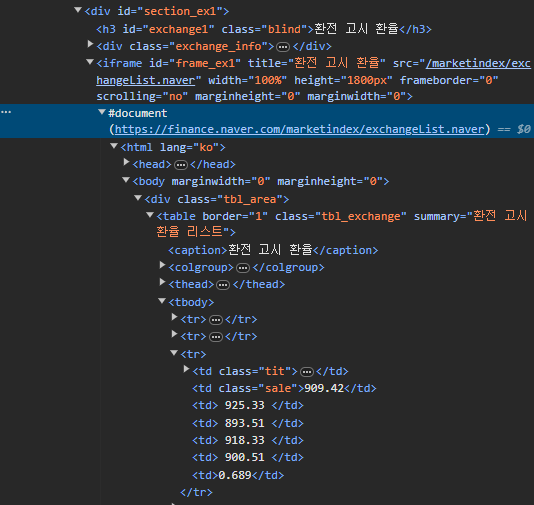
친절히 환율 리스트만 따로 제공해주는 네이버 매매기준율을 기준으로 데이터 수집을 진행해보겠습니다
데이터 수집 코드 실습
- 모듈 가져오기
파싱을 위한 BeautifulSoup와 사이트 적솝을 위한 urlopen 모듈을 가져옵니다
2. 사이트 접속
타겟사이트인 네이버 증권 시장지표 환율정보이며 네이버에서는 따로 환율 리스트 정보만을 가지고있는 사이트를 제공해주기에 타겟사이트에 입력
3. 파싱
BeautifulSoup로 html5lib을 사용한 파싱
4. 데이터 추출
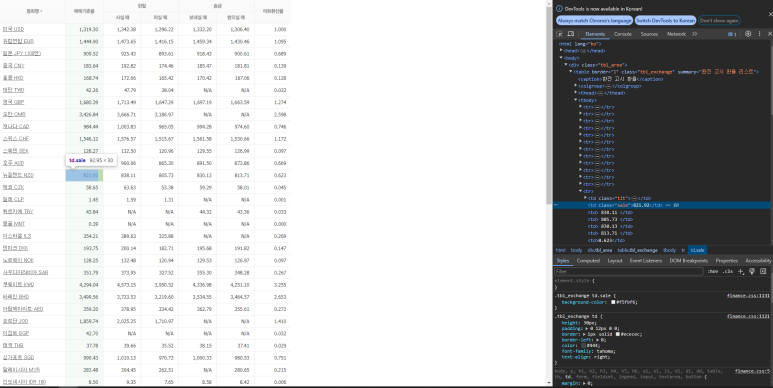
사이트에서 데이터 수집 타겟인 매매기준율의 class 이름을 확인 'sale' 클래스로 확인
바로 옆의 통화명은 tit 입니다 사이트도 제공해주더니 데이터 수집도 간단하게 만들어 둔 사이트의 예시네요
클래스 값은 이름앞에 .을 붙혀서 .sale 의 형식으로 사용이 가능합니다
이제 soup를 사용해 통화명과 매매기준율 데이터 가져올 수 있습니다
네이버 증권 환율 정보를 가져오는 간단한 웹 스크래핑 방법 이였습니다
웹 스크래핑은 간단한 사이트에서 주로 사용하는 경우가 많아서 사이트도 간단한 사이트로 선정해서 진행해보았습니다
다음에는 조금더 고급(?) 스킬인 셀레니움을 통한 데이터 수집을 진행해보겠습니다
selenium을 사용해서는 데이터 수집이 조금은 더 까다로운 웹 페이지도 가능하니 세세하게 공부해두면 더 좋을것같습니다
'Python > 데이터 수집' 카테고리의 다른 글
| 데이터 수집, 분석에 사용되는 numpy (0) | 2024.01.30 |
|---|---|
| [데이터 수집] 데이터 종류와 API 데이터 수집 (1) | 2024.01.29 |